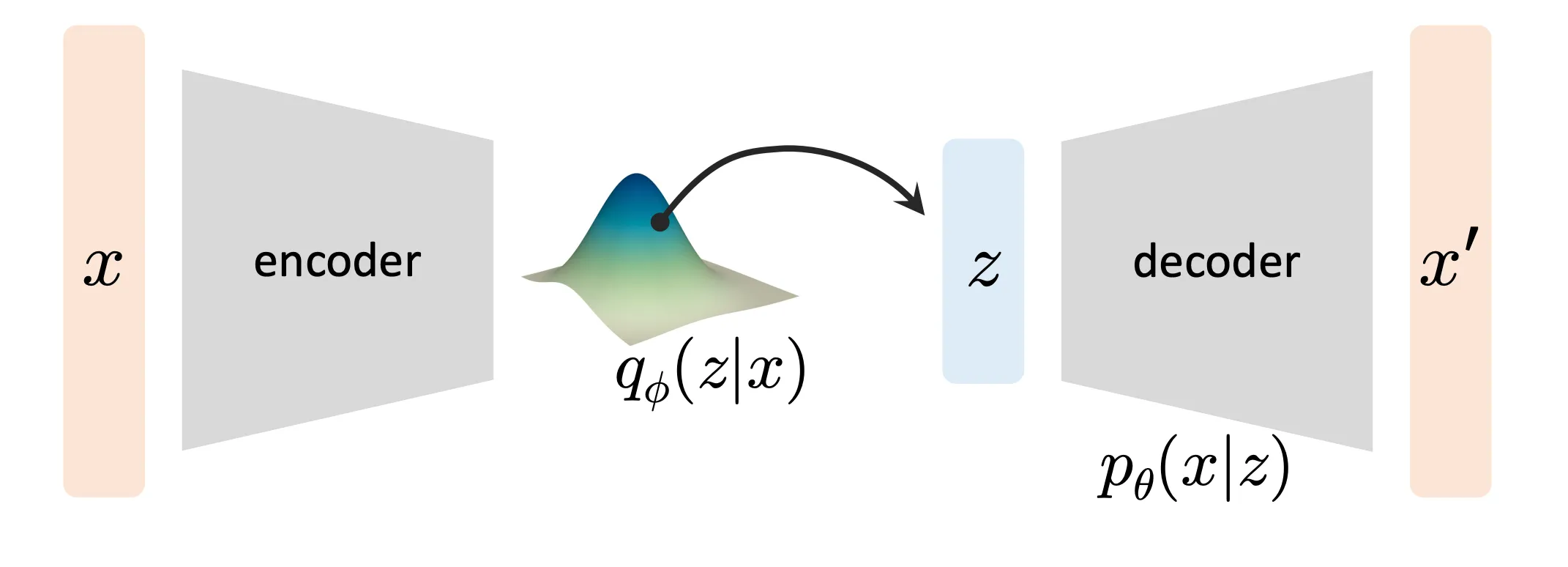
For a given set of images x, we want the generative model to find the underlying distributionp(x) of all images. Then we sample from p(x) to get a new image x′ that is unseen in the training datasets, but conform to the “overall nature” of the trained images. So the whole generation process can be thought of as mapping a distribution and then sampling from the distribution.
Conditional generation aims to map a distribution for latent feature p(z) to the image distribution p(x). The model itself can be think of as a function p(x∣z). Another question is: how to model the resemblance between distribution. One way is to use KL divergence:
DKL(p∥q)=∫xp(x)logq(x)p(x)dx
And we can simplify the KL divergence into a “likelihood” term with simple math:
We want to minimize DKL(pdata∥pθ) in parameter space θ, which is equivalent to maximize Ex∼pdatalogpθ(x). We can interoperate the term as “maximum likelihood”, which has an intuitive explanation of maximizing the possibility of observing the ground-truth data from latent distribution.
Variational Autoencoder
It is very hard to directly model the distribution for image, and even if we can model such a distribution directly with a neural network, we have no idea how to sample from it. Variational autoencoder model the problem by introducing a latent space. If we impose the latent space q(z) to be a fixed distribution (e.g. normal distribution) and somehow find the mapping from this latent distribution to image distribution, we only need to sample from this simple distribution and map the sample to image space to get the final generated image. We can think of the mapping as a function to be optimized pθ(x∣z).
Evidence Lower Bound
So now we can rephrase our objective function and see how can we optimize the mapping.
logpθ(x)=∫q(z)logpθ(x)dz(Law of Total Probability)=∫q(z)logpθ(z∣x)pθ(x∣z)p(z)dz(Baye’s Rule)=∫q(z)logpθ(z∣x)pθ(x∣z)p(z)q(z)q(z)dz=Ez∼q(z)[logpθ(x∣z)]−DKL(q(z)∥p(z))+DKL(q(z)∥pθ(z∣x))
Notice that the q(z) here is an arbitrary distribution over z, p(z) is the pre-determined latent distribution. To make this expression more interpretable, we let the p(z) to be a parameterized posterior qϕ(z∣x) of the latent value.
But why do we do this? It’s because we must have some training objective. VAE is deterministic probability transition model (different from diffusion method ddpm we will introduce later), which means that a sample from a latent space must correspond to a sample in the image space. If we directly assign q(z) to be a Gaussian, we will have to manually assign the correspondence between Gaussian noise to generated image. Instead, we choose to model q(z) to be the posterior, and let a neural network learn the correspondence itself.
Notice that the third term measure the difference between ground-truth posterior and predicted posterior, which is intractable because we don’t know anything about ground-truth posterior pθ(z∣x). But we notice that KL divergence will always be positive. So we turn to optimize the following value, which is called ELBO (Evidence Lower BOund):
The above equation is much simpler and more interpretable though.
The moved-to-left term DKL(q(z)∥pθ(z∣x)) tells us that we are actually compromising the resemblance between predicted posterior and the ground-truth posterior when we are optimizing over ELBO.
The remaining two terms is also very meaningful. The Ez∼q(z)[logpθ(x∣z)] term is a reconstruction loss. Maximize the term means maximizing the likelihood of observed training data. The DKL(q(z)∥p(z)) is regularization loss. Minimizing this term means bringing the predicted latent distribution closer to our pre-assigned normal latent distribution. We will see in later section why this is useful.
Architecture & Optimization
VAE designs a wonderful network structure that allows us to jointly optimize θ,ϕ. The neural encoder outputs the mean and diagonal covariance of the latent normal and the latent prior is often selected to be a standard multivariate Gaussian
The objective can be easily transformed to target loss.
For the reconstruction loss Ez∼q(z)[logpθ(x∣z)], we take its opposite number so that we can minimize it . Firstly, we use one-step Monte Carlo sampling to get rid of the expectation. Then we model the predicted pθ(x∣z) to be Gaussian with fixed variance N(x∣x′,σ0). Then the loss term is simply 1/2σ∥x−x′∥2+C. We can substitute it we L2 loss.
Regularization loss DKL(q(z)∥pθ(z)) can be calculated with simple math:
In VAE, we choose to model the transition function from p(z) to p(x) with a single neural network. But the transition is too hard for a single network to directly learn. Diffusion model adopts a more progressive transition. One famous interpretation for diffusion model is Hierarchical-VAE.
We spilt the whole transition into a lot of intermediate stages. At the same time, we assign each intermediate state to be a fixed distribution (To be precise, conditional intermediate state). The HVAE we get from the assumption is: DDPM.
DDPM
In essence, we want to model the process of “slowly” turning a Gaussian distribution p(z) into an image distribution p(x). But at first, let us take a step back and consider how to turn an image distribution p(x) into a Gaussian distribution p(z).
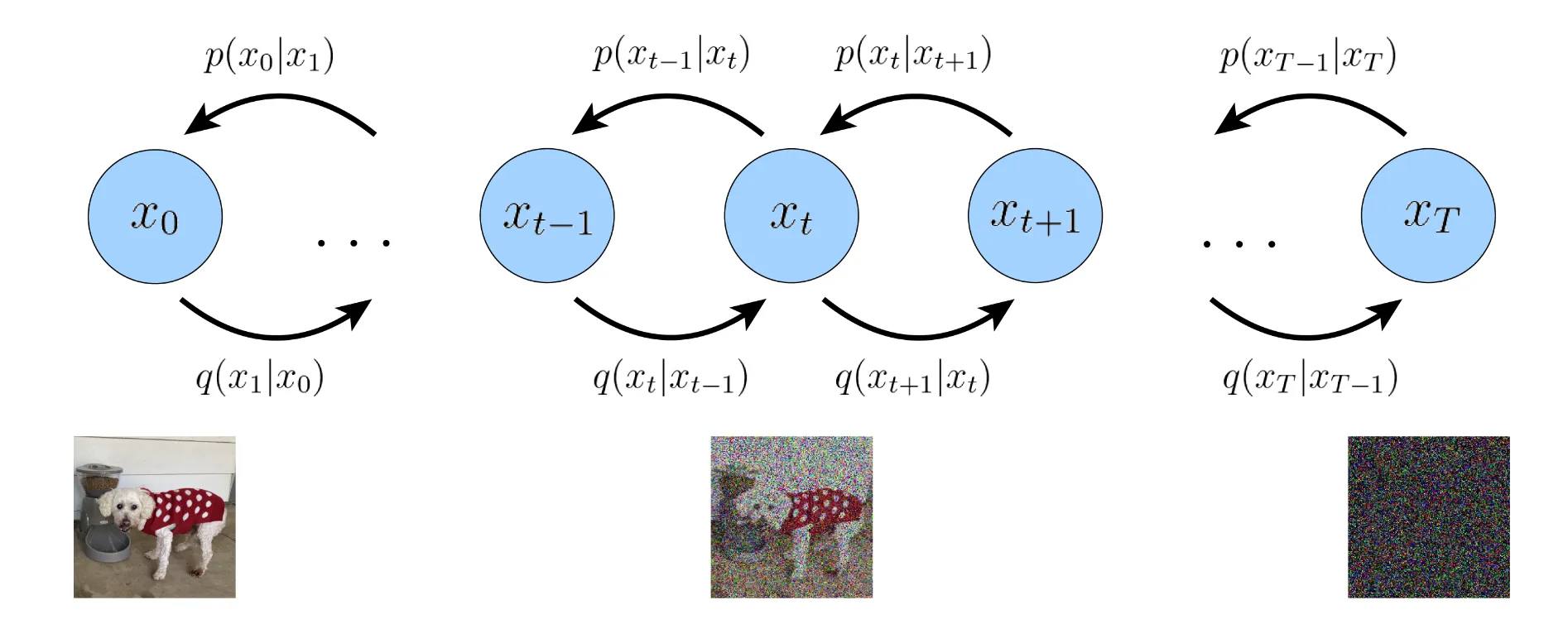
We want to achieve this through gradually adding noise to the image until it becomes pure Gaussian noise. We model the process as a Markovian process.
Noisifying and denoiding process of DDPM (Image Source from Luo et al. 2022)
For simplicity and uniformity, we let p(x) to be p(x0) and the latent distribution p(z) to be p(xT). We let the transition function q(xt∣xt−1) to be:
xt=αtxt−1+1−αtϵt−1ϵt∼N(0,I)
The reason we want to choose such a strange coefficient is that we want to preserve the variance of the random variable.
With simple math, we can easily get the distribution for each intermediate state under the condition of initial image p(xt∣x0):
xt∼N(αˉtx0,(1−αˉt)I)
Expand to see all the math
Iteratively apply the probability transition function:
xt=αtxt−1+1−αtϵt−1=αt(αt−1xt−2+1−αt−1ϵt−2)+1−αtϵt−1=αtαt−1xt−2+1−αtαt−1ϵ…=i=1∏tαix0+1−i=1∏tαiϵ=αˉtx0+1−αˉtϵ
Notice that we αt is a pre-assigned coefficient, hence the αˉt is pre-assigned. Letting αˉT take the value of 0, and we can get the final Gaussian latent distribution.
p(xt−1∣xt)=p(xt)q(xt∣xt−1)p(xt−1)
Now that we know how to turn p(x0) to p(xT), we simply need to reverse the process to turn p(xT) to p(x0), this is where the Bayes’ Rule comes to rescue. For each intermediate step:
The equation is intractable, because we don’t know p(xt−1) and p(xt). But we do know p(xt−1∣x0) and p(xt∣x0). So we can turn to calculate:
We know the interpretable representation of all 3 terms on the right side of the equation, so we can directly calculate the conditional posterior p(xt−1∣xt,x0):
Just three normal distribution combined together, here we adopt an easier way from this blog. The exponential terms of the three distribution are combined to be:
We can see that the term is clearly quadratic with respect to xt−1. Therefore the final distribution must be a normal distribution. The coefficient of the quadratic term in this expression is −21(1−αt)(1−αˉt−1)1−αˉt, so we know the variance of the distribution is:
Σ=1−αˉt(1−αt)(1−αˉt−1)I
The coefficient of the quadratic term in this expression is 1−αˉt−1αˉtx0+1−αtαtxt , we divide it with the quaduatic coefficient and then divide it by 2 to get the mean:
μ=1−αˉtαt(1−αˉt−1)xt+αˉt−1(1−αt)x0
We get the distribution from rigid math, sample from this distribution and taking iterative steps back, we have accomplished the task!
But notice that what we get is p(xt−1∣xt,x0), but during inference, we don’t know the x0(this is actually the image we want to generate). This is where the neural network comes to help. We train a gigantic leap, and train a neural network that predict x0 from xt.
Notice that p(xt∣x0) is a Gaussian, so we can use xt to interpret x0 with simple reparameterization.
x0=αˉt1(xt−1−αˉtϵ0)
Previous work has empirically shown that predicting the noise ϵ0 is better than predicting x0. We parameterize ϵ0 to be ϵθ(xt,t). And the distribution p(xt−1∣xt,x0) becomes:
So the overall training and inference procedure is:
Pseudo-code for training and inferencing process. (Image Source from Ho et al. 2020)
ELBO for HVAE
We have known from the last section that we can approximate the posterior transition distribution with a neural network that predict original image x0 from xt and t. But does this really help with our ultimate goal of maximizing log likelihood Ex∼p(x)[−logpθ(x)]? We can actually derive a closed form ELBO with the assumption we made. (Please refer to this paper for a detailed derivation.)
We can notice that each term of the ELBO has its specific meaning.
The reconstruction term measure the expected likelihood of the predicted reconstructed image. This term is jointly optimized with Monte Carlo estimate.
The prior matching term tries to keep the final notified latent space as close as possible. It contains no trainable parameter, and by carefully selecting the noising parameter α, we can diminish the term to zero.
The denoising matching term is the primary part of the ELBO. The term aims to keep the predicted distribution to align with the ground-truth conditional posterior distribution as closely as possible.
We have proved in the last section that p(xt−1∣xt,x0) is a normal distribution. Now suppose pθ(xt−1∣xt) is a normal distribution N(μt(xt,x0),σt−12I). Then we have:
The optimizing objective align with the loss function we choose in the last section(discarding all the coefficients, which was empirically shown better in the original paper).
DDIM
Now let’s talk about DDIM. Notice that during the training process, we never directly use the transition p(xt∣xt−1). This means that we actually never assume the forward(adding noise) process to be Markovian (Although we do derive most of the equation from a Markovian forward process). The only condition used during forwarding process is that the conditional distribution of xt is a normal distribution:
xt∼N(αˉtx0,(1−αˉt)I)
We can also notice that during the backward (denoising) process, the only distribution we sample from is p(xt−1∣xt,x0). Under the Markovian assumption p(xt−1∣xt,x0)=p(xt−1∣xt). But this is not necessarily true for non-Markovian forwarding process. But we can still derive a family of posterior distribution pσ(xt−1∣xt,x0) indexed by a vector σ with dimension t . (This can be proved with method of undetermined coefficients. )
Notice that if we let σt=1−αˉt(1−αt)(1−αˉt−1), the forwarding process becomes Markovian and the posterior distribution becomes that of DDPM’s.
And following the same steps, we train a neural network to predict x0(ϵ0) from xt and t. Taking in the reparameterization of x0, we get the following distribution to sample from pσ(xt−1∣xt,x0).
Another good property that DDIM has is that we can drastically accelerate the inference process:
As the denoising objective L1 does not depend on the specific forward procedure, as long as qσ(xt∣x0) is fixed, we may also consider forward processes with lengths smaller than T.
Since any forwarding process with the conditional normal distribution property can be applied to the training procedure. It certainly includes denoising process with less time-steps. We can choose these sub-sequence as our inference sequence to accelerate the inference process. (Notice that this property also applies to the DDPM inference algorithm, since DDPM is only an instance of DDIM).
Specifically, given a sequence of intermediate states (xτ1,…xτS), where τ is a sub-sequence of the original time-steps [1,…,T]. The posterior transition distribution pσ(xτt−1∣xτt,x0) can be modeled as:
Notice that in DDIM, only αˉt is preassigned, any other notations need to be derived from αˉt. For DDPM, we have σt=1−αˉt(1−αt)(1−αˉt−1)=1−αˉt(1−αˉt/αˉt−1)(1−αˉt−1). So the variance σ~τt should take the form of: